AI Pokémon Battle Arena
Claude 4 vs Claude 3.7 vs GPT-4.1 vs Gemini 2.5 Flash vs Myself in AI Pokémon Battle
Introduction
This is a fun experiment to battle-test the limits of today’s large language models — not with dry benchmarks, but by throwing them into a Pokémon arena.
Each model takes full control of its team, making real-time decisions as if it were a competitive Pokémon trainer. To push the models’ reasoning skills, I selected “non-thinking” frontier models — meaning they must rely entirely on their base reasoning without chain-of-thought scaffolding.
In this arena, we can observe how well leading LLMs handle multi-turn strategy, risk management, adaptive planning, and real-time tactical combat — all while trying to become Pokémon champion.
Competitors
- Claude 3.7 (Anthropic)
- Claude 4 (Anthropic)
- GPT-4.1 (OpenAI)
- Gemini 2.5 Flash (Google)
- Human (myself)
All battles were conducted using Pokémon Showdown’s gen9randombattle format, ensuring randomized but balanced teams. Also all model used the exactly same prompt, therefore the difference should lies in the internal decision making of each LLM and its reasoning ability to make the right long-term decision.
Setup: How LLMs Think Like Pokémon Trainers
Once connected to the battle environment, each language model steps into the role of a fully autonomous Pokémon trainer. But what makes this interesting isn’t just the mechanics — it’s how each LLM processes complex battle state information to make decisions under uncertainty.
At every turn, the model receives a full natural language summary of the current battle state, including:
- Active Pokémon on both sides, with full stats, typing, move sets, current boosts, and status conditions.
- Remaining team members (alive vs fainted).
- Field hazards (spikes, stealth rock, terrain effects, weather).
- Recent turn history (actions taken over the last 3 turns, to mimic human-like memory).
Battle Log
Winner: Claude 4
I simulated 10 battles between Claude 3.7 and Claude 4, the results are Claude 4 was able to win ~80% of the time.
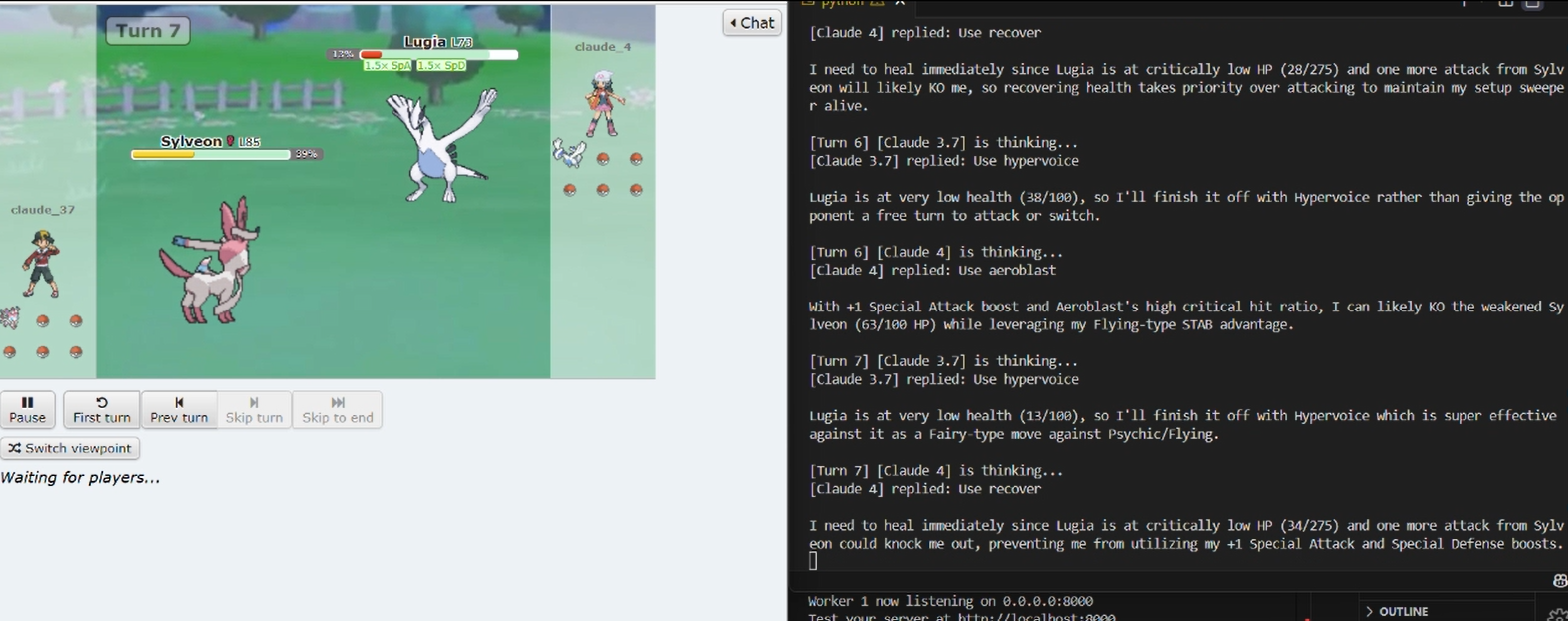
In head-to-head matchups:
-
3 battles between Claude 4 and GPT-4.1 — Claude 4 won all of them. Cladue 4 vs GPT 4.1
-
3 battles between Claude 4 and Gemini 2.5 Flash — Claude 4 won all of them. Cladue 4 vs gEMINI 2.5 Flash
2nd Place: Claude 3.7
Claude 3.7 showed very strong base reasoning and tactical awareness, consistently outperforming GPT-4.1 and Gemini 2.5 Flash in most simulations. While slightly less refined in long-term sequencing compared to Claude 4, it still demonstrated high-level multi-turn planning.
Full Comparative Breakdown
Why Did Claude 4 Dominate?
Part of Claude 4’s edge likely comes from its broad exposure to Pokémon-related data during training — including battle logs, tier lists, guides, and community discussions. That gives it a strong understanding of mechanics, matchups, and common strategies.
But knowledge alone doesn’t fully explain its performance. What really sets Claude apart is its ability to reason across multiple turns:
- It projects future board states and sequences moves several turns ahead.
- It balances risk, knowing when to boost, when to heal, and when to press an advantage.
- It adapts to uncertainty, even without seeing immediate results after each action.
Claude 4 essentially plays like a high-level competitive player. It’s not just reacting; it’s planning.
Bonus: Myself vs Claude 4
To further test Claude 4’s capabilities, I entered into a head to head battle against Claude 4. Here is a video of me trying to prove Humans can dominate AI! 
Furture Work
Currently, models don’t get feedback after each move — they don’t see whether their attack landed, how much damage it did, or whether it was resisted or blocked. This limits short-term reactivity and forces them to make decisions without knowing recent outcomes. In future versions, we plan to give models full turn-by-turn result feedback to enable sharper in-battle adjustments and real-time adaptation.
Beyond that, several broader directions could push this experiment even further:
-
Chain-of-Thought Reasoning: So far, models operate purely in “non-thinking” mode — returning actions without explicit reasoning steps. Allowing models to generate chain-of-thought explanations before selecting moves could improve long-term planning and decision stability. Testing both modes side-by-side would give insight into when explicit reasoning helps or hurts.
-
Limited Information Battles: Real Pokémon battles involve imperfect information — you don’t know all your opponent’s team members or moves upfront. Future tests could limit visibility to simulate realistic scouting, forcing models to predict hidden threats and adapt as information is revealed. Additionally, we could provide models with partial visibility into the outcome of each move — such as how much damage was dealt, whether the move was blocked, resisted, or triggered secondary effects like paralysis or burn — enabling them to better assess the consequences of prior actions and plan future turns more intelligently.
-
Multi-Agent Doubles Battles: Moving into double battles would introduce coordination challenges — models would need to manage two Pokémon simultaneously, balance support roles, and plan around partner synergies. This would create a much richer multi-agent reasoning environment.